网上大多是低版本的pycharm设置国内清华源的方法 对于:PyCharm 2023.3.2 (Community Edition) 没多大参考。特此记录一下
网上大多是低版本的pycharm设置国内清华源的方法 对于:PyCharm 2023.3.2 (Community Edition) 没多大参考。特此记录一下
昨天有一个小需求,有两段会议录音,总时间2.5小时。需要把录音转成文字。搜索了一下。没有太好的现成的解决方案。但是:如果你是技术爱好者或对隐私、长音频有要求,功能强大的开源工具 Whisper-CTranslate2 会是一个绝佳选择。它完全免费且在本地运行,不上传数据,处理长音频(如1小时的课程)也很快。就是这个了。
我的环境:macos sequoia 15.6 m1 16g Anaconda-Navigator PyCharm CE
将按照以下步骤进行:
注意:由于M1芯片是ARM架构,我们确保安装的库是支持ARM的。我们可以通过conda或pip安装,但建议使用conda来管理依赖,以避免兼容性问题。以下是详细的步骤,我们将通过命令行操作:步骤1:创建Conda环境打开终端,运行以下命令:
conda create -n whisper_env python=3.9 conda activate whisper_env
步骤2:安装whisper-ctranslate2我们可以使用pip安装whisper-ctranslate2,同时安装librosa用于音频加载(whisper-ctranslate2本身会依赖一些库,但librosa可能需要单独安装以确保音频加载功能)。
pip install whisper-ctranslate2
pip install librosa
步骤3:安装PyTorch(可选,但如果你需要使用GPU加速,M1芯片可以使用MPS加速)虽然Whisper-CTranslate2主要使用CTranslate2进行加速,但它的依赖中可能包括PyTorch。不过,为了确保在M1上获得最佳性能,我们可以安装支持MPS的PyTorch版本。但请注意,Whisper-CTranslate2并不直接依赖PyTorch的MPS,因为它是基于CTranslate2的,而CTranslate2在M1上使用CPU(通过Accelerate Framework)已经很快了。如果你还是想安装PyTorch,可以使用以下命令:
conda install pytorch::pytorch -c pytorch
但根据Whisper-CTranslate2的文档,它并不要求PyTorch,所以这一步是可选的。
我没用。。 我直接用cpu 处理。
步骤4:测试安装安装完成后,我们可以通过命令行测试whisper-ctranslate2是否安装成功:
whisper-ctranslate2 --help
如果出现帮助信息,则安装成功。
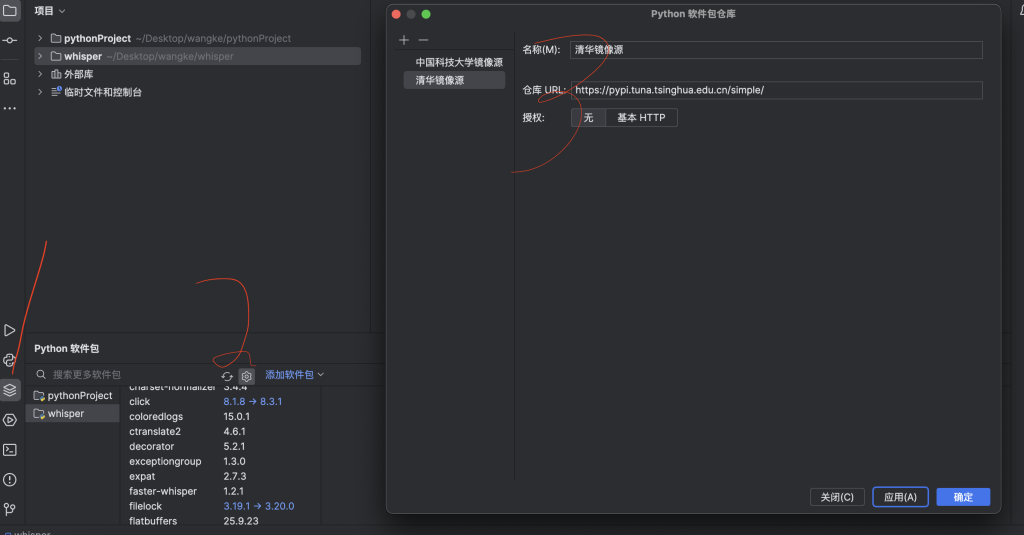
需要注意第二步。最好用国内源。 我卡这好久。
然后就是在PyCharm CE中配置项目
环境配置好后,我们来确认一切是否就绪,并看看如何转录音频。
from faster_whisper import WhisperModel
print("环境配置成功!")如果没有报错,说明安装成功。
2.最终我的代码:
import os
from faster_whisper import WhisperModel
import time
def transcribe_audio_with_progress(input_audio_path, output_text_path, model_path, device="cpu", language="zh"):
"""
转录音频文件为文字,带有进度提示和实时保存功能
参数:
input_audio_path: 输入的音频文件路径
output_text_path: 输出的文本文件路径
model_path: 本地模型文件路径
device: 运行设备,"cpu" 或 "cuda"
language: 音频语言代码,"zh" 表示中文
"""
print(f"开始加载模型...")
start_time = time.time()
# 使用本地模型路径初始化模型
model = WhisperModel(model_path, device=device, compute_type="int8")
model_load_time = time.time() - start_time
print(f"模型加载完成,耗时: {model_load_time:.2f}秒")
print(f"开始处理音频文件: {os.path.basename(input_audio_path)}")
print("转录进行中,请耐心等待...")
# 转录音频文件
segments, info = model.transcribe(
input_audio_path,
vad_filter=True,
vad_parameters=dict(min_silence_duration_ms=500),
beam_size=5,
language=language
)
# 创建输出目录(如果不存在)
os.makedirs(os.path.dirname(output_text_path), exist_ok=True)
# 打开文件准备写入
with open(output_text_path, "w", encoding="utf-8") as f:
# 写入文件头部信息
f.write(f"音频文件: {os.path.basename(input_audio_path)}\n")
f.write(f"检测到语言: {info.language}, 置信度: {info.language_probability:.2f}\n")
f.write(f"转录开始时间: {time.strftime('%Y-%m-%d %H:%M:%S')}\n")
f.write("=" * 50 + "\n\n")
# 处理每个片段
segment_count = 0
start_processing_time = time.time()
last_progress_time = time.time()
for segment in segments:
segment_count += 1
# 每10个片段或每30秒打印一次进度
current_time = time.time()
if segment_count % 10 == 0 or current_time - last_progress_time > 30:
elapsed_time = current_time - start_processing_time
print(f"已处理 {segment_count} 个片段,当前时间点: {segment.start:.2f}秒,已用时间: {elapsed_time:.1f}秒")
last_progress_time = current_time
# 格式化片段信息
segment_text = f"[{segment.start:.2f}s -> {segment.end:.2f}s] {segment.text}\n"
# 写入文件并立即刷新缓冲区,确保实时保存
f.write(segment_text)
f.flush()
# 转录完成
total_time = time.time() - start_time
print(f"\n转录完成!")
print(f"总共处理了 {segment_count} 个片段")
print(f"总耗时: {total_time:.2f}秒")
print(f"结果已保存到: {output_text_path}")
# 在文件末尾添加统计信息
with open(output_text_path, "a", encoding="utf-8") as f:
f.write("\n" + "=" * 50 + "\n")
f.write(f"转录完成时间: {time.strftime('%Y-%m-%d %H:%M:%S')}\n")
f.write(f"总片段数: {segment_count}\n")
f.write(f"总处理时间: {total_time:.2f}秒\n")
# 使用示例
if __name__ == "__main__":
# 设置路径
input_audio = "/url/25111701.mp3"
output_text = "/url/25111701_transcription.txt"
local_model_path = "/Url/faster-whisper-medium" # 修改为您实际存放模型的路径
# 检查模型是否存在
if not os.path.exists(local_model_path):
print(f"错误: 模型路径不存在: {local_model_path}")
print("请先按照说明手动下载模型文件")
else:
print(f"使用本地模型: {local_model_path}")
# 执行转录
transcribe_audio_with_progress(
input_audio_path=input_audio,
output_text_path=output_text,
model_path=local_model_path,
device="cpu",
language="zh"
)注意啊。这当中还有个坑。faster-whisper-medium这个模型是需要手动下载下来的啊。
好了。就这样,速度还不错
已处理 640 个片段,当前时间点: 5327.49秒,已用时间: 2965.3秒
转录完成!
总共处理了 641 个片段
总耗时: 3002.00秒
结果已保存到: /Url/
今天空间突然能进,并提示:
尊敬的用户,您的空间信息因违反了QQ空间使用规则,部分功能已被限制,0天后系统自动解除,请您及时查毒后修改密码,并对空间中违规信息进行删除处理,也可清理后点下方申诉,我们会在一个工作日内完成处理,请勿重复提交,感谢您配合与支持!
搜索发现有可能是说说有问题
发现有大量的说说内容。只能一条条删除随即找了以下代码,能正确运行批量删除说说:
(async () => {
let frameDocument = document.querySelector('.app_canvas_frame').contentWindow.document;
while (true) {
frameDocument.querySelectorAll('.del_btn').forEach(item => item.click());
await sleep(1500);
document.querySelectorAll('.qz_dialog_layer_sub').forEach(item => item.click());
await sleep(1500);
nextPage();
await sleep(1000);
}
function nextPage() {
let aTags = frameDocument.querySelectorAll('.mod_pagenav_main > a');
// Convert NodeList to an array for iteration
let aTagsArray = Array.from(aTags);
for (let item of aTagsArray) {
if (item.innerText == '下一页') {
item.click();
break;
}
}
}
function sleep(time) {
return new Promise(resolve => setTimeout(resolve, time));
}
})();先删除,后面看是否解封。
欢迎使用 WordPress。这是您的第一篇文章。编辑或删除它,然后开始写作吧!